SpringCloud Hystrix 基本使用
什么是雪崩?
在学习 Hystrix 之前先来看下什么是雪崩
在分布式架构中,很常见的一个情形就是某一个请求需要调用多个服务。
如客户端访问 user 服务,而 user 服务需要调用 order 服务,order 服务需要调用 goods 服务,由于网络原因或者自身的原因,如果 order 服务或者 goods 服务不能及时响应,user 服务将处于阻塞状态,直到 order 服务 goods 服务响应。
此时若有大量的请求涌入,容器的线程资源会被消耗完毕,导致服务瘫痪。
注:如果使用 Tomcat 的线程池去接收用户的请求(Tomcat 是一个线程一个请求,即大力出奇迹),如果某一个服务出现了故障,这个时候后续有大量的请求过来,那么容器中的线程数量则会持续增加直致 CPU 资源耗尽到 100% (雪崩),导致 Tomcat 无法处理其他业务功能
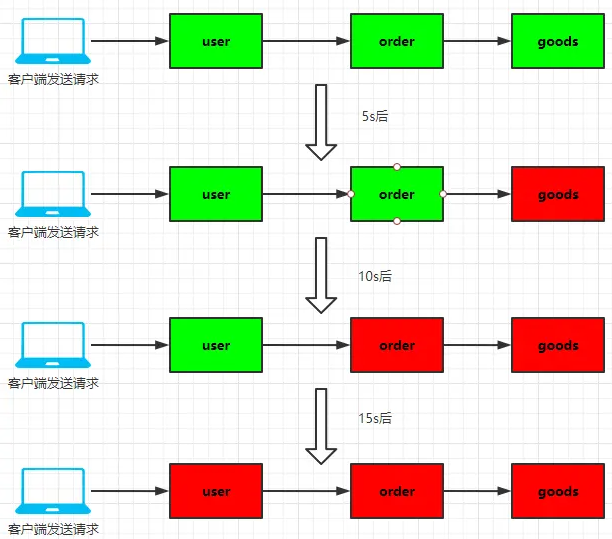
1 如图所示,此时的系统正在愉快的运行中。
2 突然这个时候,goods 服务节点的网络发生了故障。goods 服务节点瘫痪,goods 服务不可用。
3 由于 good 服务瘫痪导致 order 服务向 goods 服务发送的请求得不到返回,一直处于阻塞,此时 user 服务仍然一直 向 order 服务发送请求,最终导致 order 服务节点的资源耗尽,order 服务节点瘫痪,order 服务不可用。
4 由于 good 服务瘫痪导致 order 服务向 goods 服务发送的请求得不到返回,一直处于阻塞,此时 user 服务仍然一直向 order 服务发送请求,最终导致 order 服务节点的资源耗尽,也瘫痪掉。此时 user 服务向 order 服务发送的请求同样也得不到返回,而客户端依然源源不断的向 user 服务节点发送请求,最终 user 服务节点和 order 服务节点一样,由于资源耗尽导致服务器瘫痪,user服务也不可用。
服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的 “雪崩” 效应。
为什么会产生服务雪崩?
流量激增:比如异常流量、用户重试导致系统负载升高;
缓存穿透:假设A为client端,B为Server端,假设A系统请求都流向B系统,请求超出了B系统的承载能力,就会造成B系统崩溃;
程序有Bug:代码循环调用的逻辑问题,资源未释放引起的内存泄漏等问题;
硬件故障:比如宕机,机房断电,光纤被挖断等。
数据库严重瓶颈,比如:长事务、慢sql等。
线程同步等待:系统间经常采用同步服务调用模式,核心服务和非核心服务共用一个线程池和消息队列。如果一个核心业务线程调用非核心线程,这个非核心线程交由第三方系统完成,当第三方系统本身出现问题,导致核心线程阻塞,一直处于等待状态,而进程间的调用是有超时限制的,最终这条线程将断掉,也可能引发雪崩。
服务雪崩的应对策略
针对造成服务雪崩的不同原因,可以使用不同的应对策略:
- 流量控制
- 改进缓存模式
- 服务自动扩容
- 服务调用者降级服务
流量控制 的具体措施包括:
- 网关限流(主要在 Nginx 层面)
- 用户交互限流
- 关闭重试
这里的用户交互限流的具体措施有:
- 采用加载动画,提高用户的忍耐等待时间.
- 提交按钮添加强制等待时间机制.
改进缓存模式 的措施包括:
- 缓存预加载
- 同步改为异步刷新
服务自动扩容 的措施主要有:
- AWS的 auto scaling
- 对 ECS集群中的应用进行弹性伸缩
服务调用者降级服务 的措施包括:
- 资源隔离
- 对依赖服务进行分类
- 不可用服务的调用快速失败
资源隔离主要是对调用服务的线程池进行隔离。
可以根据具体业务,将依赖服务分为: 强依赖和弱依赖。强依赖服务不可用会导致当前业务中止,而弱依赖服务的不可用不会导致当前业务的中止。
不可用服务的调用快速失败一般通过 超时机制、熔断器 和 熔断后的 降级方法 来实现。
Hystrix 的主要作用
- 服务隔离和服务熔断
- 服务降级、限流和快速失败
- 请求合并和请求缓存
- 自带单体和集群监控
Hystrix 设计原则是什么
- 防止任何单个依赖项耗尽所有容器(如Tomcat)用户线程。
- 甩掉包袱,快速失败而不是排队。
- 在任何可行的地方提供回退,以保护用户不受失败的影响。
- 使用隔离技术(如隔离板、泳道和断路器模式)来限制任何一个依赖项的影响。
- 通过近实时的度量、监视和警报来优化发现时间。
- 通过配置的低延迟传播来优化恢复时间。
- 支持对Hystrix的大多数方面的动态属性更改,允许使用低延迟反馈循环进行实时操作修改。
- 避免在整个依赖客户端执行中出现故障,而不仅仅是在网络流量中。
Hystrix 的重要概念
- 服务降级 fallback
- 服务熔断 break
- 服务限流 flowlimit
服务降级:所谓降级,就是整体资源快不够用了,忍痛将某些服务先关掉,待度过难关,在开启回来。一般是从整体符合考虑,当某个服务熔断之后,服务器将不再被调用,此刻客户端可以自己准备一个本地的 fallback 回调,返回一个缺省值,这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强。
服务熔断:服务熔断的作用类似于家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
服务限流:服务限流是指在一定时间段内限制服务的请求量以保护系统,主要用于防止突发流量而导致的服务崩溃,比如秒杀、抢购、双十一等场景,也可以用于安全目的,比如应对外部暴力攻击。
Hystrix 是怎么工作的
Hystrix 是隔离、熔断以及降级的一个框架。
隔离:Hystrix 会搞很多个小小的线程池,比如订单服务请求库存服务是一个线程池,请求仓储服务是一个线程池,请求积分服务是一个线程池。每个线程池里的线程就仅仅用于请求那个服务。这样某个服务挂了也只是这个服务的线程池莫得了,其他的线程池还是能正常工作
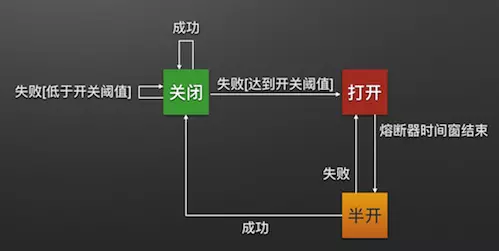
熔断器:熔断器模式定义了熔断器开关相互转换的逻辑:
服务的健康状况 = 请求失败数 / 请求总数(就是求百分比)
熔断器开关由关闭到打开的状态转换是通过当前服务健康状况和设定阈值比较决定的
Hystrix的内部处理逻辑:
关闭:当熔断器开关关闭时,请求被允许通过熔断器。如果当前健康状况高于设定阈值m开关继续保持关闭。如果当前健康状况低于设定阈值开关则切换为打开状态。
打开:当熔断器开关打开时,请求被禁止通过。
半开:当熔断器开关处于打开状态,经过一段时间后,熔断器会自动进入半开状态,这时熔断器只允许一个请求通过。当该请求调用成功时,熔断器恢复到关闭状态。若该请求失败,熔断器继续保持打开状态,接下来的请求被禁止通过。
熔断器的开关能保证服务调用者在调用异常服务时,快速返回结果,避免大量的同步等待。并且熔断器能在一段时间后继续侦测请求执行结果,提供恢复服务调用的可能。
服务降级:如果某个服务挂了(熔断器判断),Hystrix 还提供降级服务,即调用失败返回的默认数据

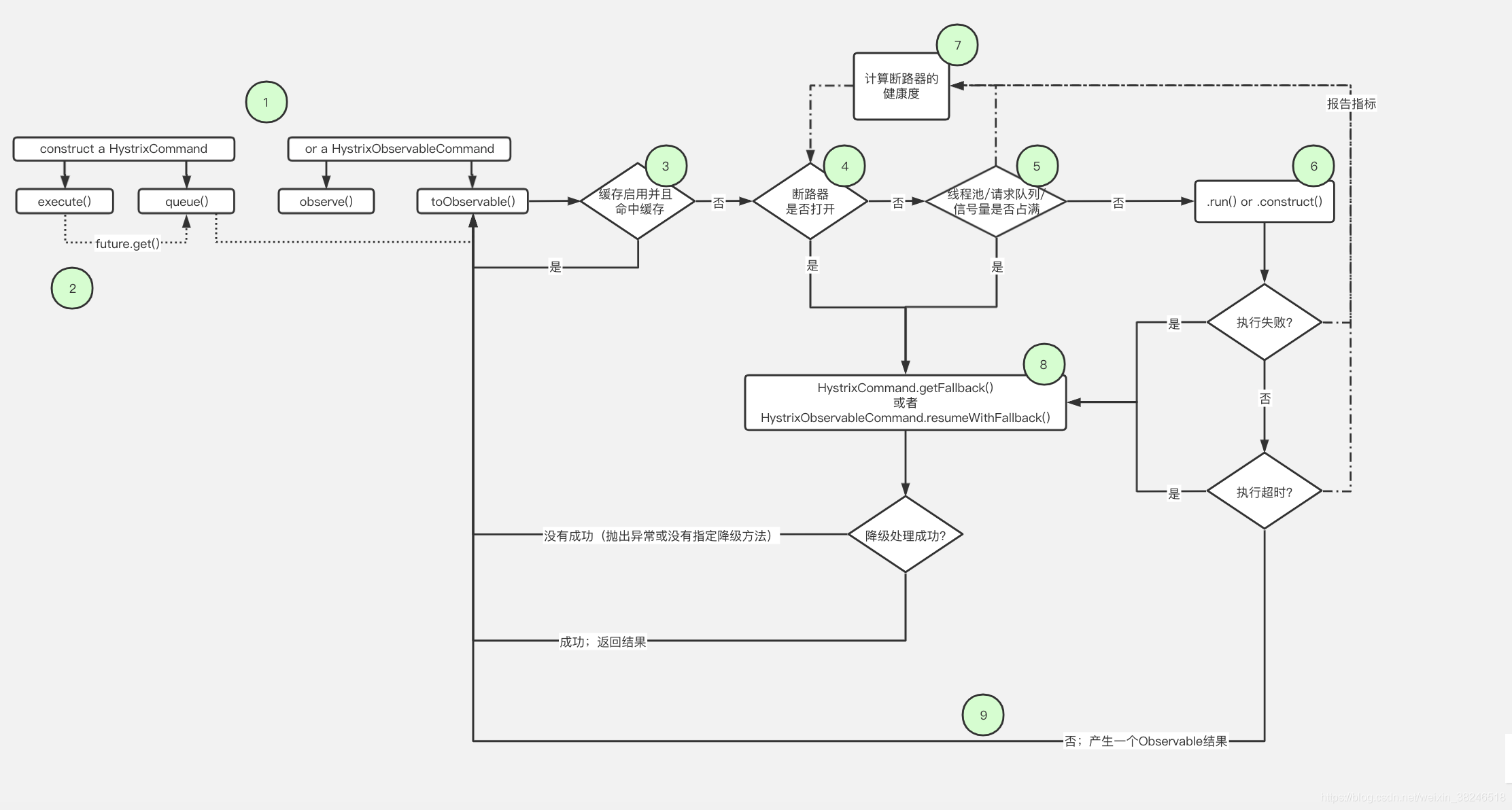
整个 Hystrix 工作流程图
配置环境
<!-- https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-starter-netflix-hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<!-- Hystrix-Dashboard -->
<!-- 注意这个不是必须的,它就是一个监控工具 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
集成成功与否的必要性测试
上面引入了 Hystrix-Dashboard 微服务监控依赖,我们可以通过访问 Hystrix-Dashboard 微服务监控平台来检测 Hystrix 是否配置成功。
如果的 Hystrix 是配置成功的话,那么,可以通过输入应用实例地址加端口,且最后以 /hystrix 形式结尾的链接,即可看到 Hystrix Dashboard 监控面板。

常用注解一览
| 注解名称 | 适用位置 | 作用 |
|---|---|---|
| @EnableHystrix | 类 | 通知应用使用 Hystrix 熔断器 |
| @EnableHystrixDashboard | 类 | 通知应用使用 Hystrix 服务监控台 |
| @HystrixCommand | 方法 | 设置方法的服务容错机制 |
| @HystrixProperty | 方法 | 设置 Hystrix 中的参数 |
| @HystrixCollapser | 方法 | 合并请求 |
如果想要在 Spring Cloud 框架中使用 Hystrix ,就必须要先声明 @EnableHystrix 注解
@EnableHystrix
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
@EnableHystrixDashboard 注解和 @EnableHystrix 注解的作用类似,即也可以理解为它是一个开关,用来控制在项目中是否使用 HstrixDashboard 服务监控台,如果声明了该注解,则表示使用 HstrixDashboard 服务监控台(默认控制台是关闭的)
@EnableHystrixDashboard
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
注意使用这个得先引入 dashboard 依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-hystrix-dashboard</artifactId>
</dependency>
具体使用之后会讲
HystrixCommand 注解配置
@HystrixCommand 注解是 Hystrix 注解中的核心注解,可以说只要想使用 Hystrix 的功能特性,就必须要使用该注解。这个注解提供了丰富的属性,如下表所示:
| 属性名称 | 属性类型 | 默认值 | 作用 |
|---|---|---|---|
| fallbackMethod | String | 空字符串 | 配置服务容错机制 |
| defaultFallback | String | 空字符串 | 配置默认服务容错机制 |
| threadPoolKey | String | 空字符串 | 配置线程池隔离策略 |
| threadPoolProperties | HystrixProperty[] | 空数组 | 配置线程池详细策略 |
配置使用一览
@HystrixCommand(groupKey = "hello",commandKey = "hello-service",threadPoolKey = "hello-pool",
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "30"),
@HystrixProperty(name = "maxQueueSize", value = "101"),
@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "15"),
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "12"),
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "1440")
},
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "5000"),
@HystrixProperty(name = "execution.isolation.strategy",value = "THREAD")
},
fallbackMethod = "helloFallBack"
)
fallbackMethod 属性
该属性的作用就是配置项目中,服务的容错机制。
这里以一个简单的 helloWorld 请求为例,我们先来看正常请求。
@RequestMapping(value = "hello", method = RequestMethod.GET)
@ResponseBody
public String hello() {
return "helloWorld";
}
模拟以下请求错误的情况,即在请求时,我们认为设置一个延时时间,来让 Hystrix 捕捉到这一异常,并应用 Hystrix 的容错机制。
@RequestMapping(value = "hello", method = RequestMethod.GET)
@ResponseBody
@HystrixCommand(fallbackMethod = "helloFail")
public String hello() throws InterruptedException {
Thread.sleep(1000);
return "helloWorld";
}
public String helloFail(){
return "helloFailed";
}
使用 HystrixCommand 注解的 fallbackMethod 属性来定义当请求不能正常响应时的应急方案,fallbackMethod 属性的值就是请求不能正常响应时,所返回的方法,这里的 helloFail 就是方法名。
手动加入了一个延时时间,该延时时间可以在响应请求时,延迟一秒响应,这就是我们手动实现的一个服务异常情况,该情况会被 Hystrix 的容错机制捕捉到。
defaultFallback 属性
defaultFallback 属性和 fallbackMethod 属性所实现的功能是基本相同的,只不过 defaultFallback 属性是用来配置默认的应急方法,即当我们的项目中存在多个应急方法时,我们给其中一个请求所配置的默认应急方法。
threadPoolKey 和 threadPoolProperties属性
threadPoolKey 属性是用来配置线程池隔离策略的属性。
threadPoolProperties 属性,则是用来配置线程池详细策略的属性,例如,核心线程数量、最大线程数量等。
@RequestMapping(value = "hello", method = RequestMethod.GET)
@ResponseBody
@HystrixCommand(fallbackMethod = "helloFail", threadPoolKey = "HelloHystrix")
public String hello() throws InterruptedException {
Thread.sleep(1000);
return "helloWorld";
}
public String helloFail(){
return "helloFailed";
}
使用 HystrixCommand 的 threadPoolKey 属性来配置线程池隔离,即我们将 helloWorld 请求划到了名为 HelloHystrix 的线程池下,这样就和主线程分离开了(其实就是分组,方便监控用的)
再来看一下 threadPoolProperties 属性的具体用法。
@RequestMapping(value = "hello", method = RequestMethod.GET)
@ResponseBody
@HystrixCommand(fallbackMethod = "helloFail", threadPoolProperties = {
@HystrixProperty(name = "coresize", value = "2"),
@HystrixProperty(name = "allowMaximumSizeToDivergeFromCoreSize", value = "true"),
@HystrixProperty(name = "maximumSize", value = "2")
})
public String hello() throws InterruptedException {
Thread.sleep(1000);
return "helloWorld";
}
public String helloFail(){
return "helloFailed";
}
为 threadPoolProperties 定义了几个常用的线程池隔离策略,它们分别是:核心线程数、开启最大线程数、最大线程数。
这个配置 @HystrixProperty 配置详情参考 官方文档 Configuration
HystrixProperty 注解详解
@HystrixProperty 注解其实是一个辅助配置注解,他的主要作用就是对参数配置场景下,对每个配置策略进行单独的声明,他的用法就是上述 threadPoolProperties 属性所配置的那样。
@HystrixProperty 注解只有两个属性,分别是 name 和 value ,name 的值是 Hystrix 官网定义好的配置项的 key ,而 value 值则是配置对应的具体参数值。
@HystrixProperty 注解中 name 属性的描述不能随意描述,要根据官网所定义的配置项来描述,不可无中生有。
Reference
参考资料 GitHub Hystrix 项目页(里面也有教程) 参考资料 官方文档 参考资料 防雪崩利器:熔断器 Hystrix 的原理与使用 参考资料 什么是服务雪崩? 参考资料 Hystrix设计原则是什么 参考资料 Spring Cloud 集成 Hystrix(慕课的这个教程超级棒!)